MovieChat: From Dense Token to Sparse Memory for Long Video Understanding
Feb 27, 2024·,,,,,,·
0 min read
Enxin Song
Wenhao Chai
Guanhong Wang
Yucheng Zhang
Haoyang Zhou
Feiyang Wu
Gaoang Wang
Abstract
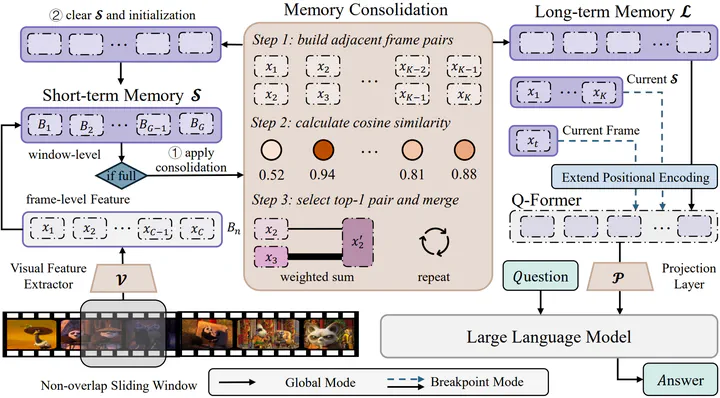
Recently, integrating video foundation models and large language models to build a video understanding system can overcome the limitations of specific pre-defined vision tasks. Yet, existing systems can only handle videos with very few frames. For long videos, the computation complexity, memory cost, and long-term temporal connection impose additional challenges. Taking advantage of the AtkinsonShiffrin memory model, with tokens in Transformers being employed as the carriers of memory in combination with our specially designed memory mechanism, we propose the MovieChat to overcome these challenges. MovieChat achieves state-of-the-art performance in long video understanding, along with the released MovieChat-1K benchmark with 1K long video and 14K manual annotations for validation of the effectiveness of our method.
Type
Publication
In CVPR2024